


The WITH clause lets you assign a name to a subquery block. You can then reference the subquery block multiple places in the query by specifying the query name. Oracle Database optimizes the query by treating the query name as either an inline view or as a temporary table. You can specify this clause in any top-level SELECT statement and in most types of subqueries. The query name is visible to the main query and to all subsequent subqueries except the subquery that defines the query name itself. The query syntax is as follows:


One of the exam requirements is "Use the data dictionary views to research data on your objects". Knowing dictionary views and tables is essential as dictionary data contains information about the database (concept of metadata) and its state. They are used for management, tunning and monitoring of the database. The data dictionary is created when the Oracle database is created. It is owned by the SYS user, and is stored principally in the SYSTEM tablespace, though some components are stored in the SYSAUX tablespace in Oracle Database 10g.The data dictionary views come in three main flavors:
Examine the data in the DOCNO column of the DOC_DETAILS table:
DOCNO
123-456-7890
233-67-90876
45-789-23456
You need to extract the digits between the hyphens as follows:
SUBSTR
456
67
789
Which SQL statement gives the required result?
A. SELECT REGEXP_SUBSTR(docno,'-[^-]+') "SUBSTR" FROM doc_details;
B. SELECT REGEXP_SUBSTR(docno,'^-[^-]+-')"SUBSTR" FROM doc_details;
C. SELECT REGEXP_SUBSTR(docno,'-[^-]+',2) "SUBSTR" FROM doc_details;
D. SELECT REGEXP_SUBSTR(docno, '[^-]+',1,2) "SUBSTR" FROM doc_details;
Theory:
Since the question contains queries with REGEXP_SUBSTR function and regular expression syntax, so the information required to answer it can found as follows: REGEXP_SUBSTR and REGULAR EXPRESSION SYNTAX.

View the Exhibit and examine the structure of the EMP table belonging to the user SCOTT. The EMP table contains the details of all the current employees in your organization. EMPNO is the PRIMARY KEY. User SCOTT has created an ENAME_IDX index on the ENAME column and an EMP_VW view that displays the ENAME and SALARY columns. The recyclebin is enabled in the database. SCOTT executes the following command:
SQL> DROP TABLE emp;
Which details would be stored in the recycle bin? (Choose all that apply)
A. EMP_VW
B. ENAME_IDX
C. The PRIMARY KEY constraint
D. Only the structure of the EMP table
E. Structure and data of the EMP table
Exhibit:

Examine the structure of the DEPT table:

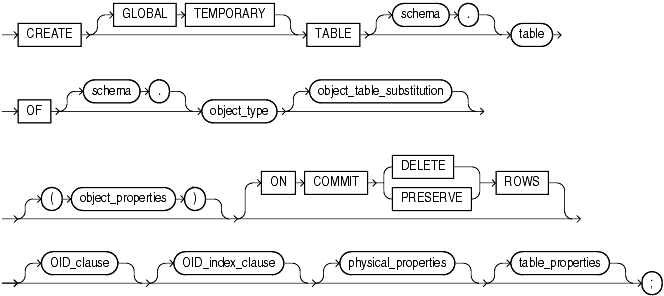

Evaluate the following SQL statement:
(Note that the numbers 2,3 etc in the SQL statement are line numbers and not part of the syntax)
SQL> CREATE TABLE product
2 (prod_id NUMBER(3),
3 prod_name VARCHAR2(25),
4 qty NUMBER(7,2),
5 price NUMBER(10,2),
6 CONSTRAINT prod_id_pk PRIMARY KEY(prod_id),
7 CONSTRAINT prod_name_uq UNIQUE (prod_name),
8 CONSTRAINT price_nn NOT NULL (price));
What is the outcome of executing this command?
A. It generates an error at line 6.
B. It generates an error at line 7.
C. It generates an error at line 8.
D. It executes successfully and creates the PRODUCTS table.
Theory:
Since the question asks about the syntax of creating a table and constrains, the information required to answer the question can be found as follows: CREATE TABLE and CONSTRAINTS.




View the Exhibit and examine the structure of the EMP table. You want to display the names and salaries of only those employees who earn the highest salaries in their departments. Which two SQL statements give the required output? (Choose two.)
A. SELECT ename, sal
FROM emp e
WHERE sal = (SELECT MAX(sal)
FROM emp
WHERE deptno = e.deptno);
B. SELECT ename, sal
FROM emp
WHERE sal = ALL (SELECT MAX(sal)
FROM emp
GROUP BY deptno);
C. SELECT ename, sal
FROM emp e
WHERE EXISTS (SELECT MAX(sal)
FROM emp WHERE deptno = e.deptno);
D. SELECT ename, sal
FROM emp
NATURAL JOIN (SELECT deptno, MAX(sal) sal
FROM emp
GROUP BY deptno);
Exhibits:
EMP table:





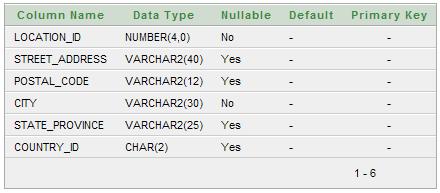
View the Exhibit and examine the structure of the LOCATIONS and DEPARTMENTS tables. You need to display all those cities that have only one department. Which query gives the correct output?
A.SELECT location_id, city
FROM locations l
WHERE 1 = (SELECT COUNT(*)
FROM departments
WHERE location_id = l.location_id);
B. SELECT location_id, city
FROM locations WHERE EXISTS (SELECT COUNT(*)
FROM departments
GROUP BY location_id HAVING COUNT(*) = 1);
C. SELECT location_id, city
FROM locations WHERE
1 = (SELECT COUNT(*) FROM departments
GROUP BY location_id);
D. SELECT l.location_id, city
FROM locations l JOIN departments d ON (l.location_id = d.location_id)
WHERE EXISTS (SELECT COUNT(*)
FROM departments d
WHERE l.location_id =d.location_id);
Exhibit:
LOCATIONS table:





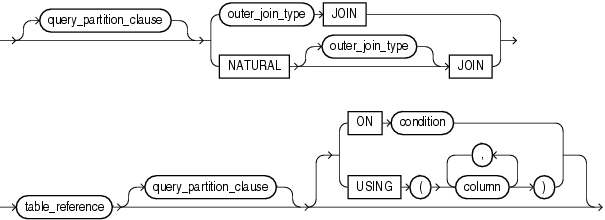
View the Exhibit and examine the structure of the EMPLOYEES and DEPARTMENTS tables. You want to display the last names and hire dates of all latest hires in their respective departments in the location ID 1700. You issue the following query:
SQL>SELECT last_name, hire_date
FROM employees
WHERE (department_id, hire_date) IN
(SELECT department_id, MAX(hire_date)
FROM employees JOIN departments
USING(department_id)
WHERE location_id = 1700
GROUP BY department_id);
What is the outcome?
A. It executes but does not give the correct result
B. It executes successfully and gives the correct result
C. It generates an error because of the pairwise comparison
D. It generates an error because the GROUP BY clause cannot be used with table joins in a subquery
Exhibit:
EMPLOYEES table:




View the Exhibit and examine the structure of the DEPARTMENTS and LOCATIONS tables. You want to display all the cities and the corresponding departments in them, if any. Which query would give you the required output?
A. SELECT location_id LOC, city, department_id DEPT
FROM locations LEFT OUTER JOIN departments
USING (location_id);
B. SELECT location_id LOC, city, department_id DEPT
FROM locations RIGHT OUTER JOIN departments
USING (location_id);
C. SELECT l.location_id LOC, l.city, d.department_id DEPT
FROM locations l LEFT OUTER JOIN departments d
USING (location_id);
D. SELECT l.location_id LOC, l.city, d.department_id DEPT
FROM locations l FULL OUTER JOIN departments d
USING (location_id);
Exhibit:
DEPARTMENTS table:



1. View the Exhibit and examine the structure of the EMP and SALGRADE tables. You want to display the names of all employees whose salaries belong to GRADE 5. Which SQL statements give the required output? (Choose all that apply)
A.SELECT ename
FROM emp JOIN salgrade
USING (sal BETWEEN losal AND hisal) AND grade = 5;
B. SELECT ename
FROM emp e JOIN salgrade s
ON (e.sal BETWEEN s.losal AND s.hisal AND s.grade = 5);
C. SELECT ename
FROM emp e JOIN salgrade s
ON (e.sal BETWEEN s.losal AND s.hisal) AND s.grade = 5;
D. SELECT ename
FROM emp e JOIN salgrade s
ON (e.sal BETWEEN s.losal AND s.hisal) WHERE s.grade=5;
E. SELECT ename
FROM emp e JOIN salgrade s
WHERE e.sal BETWEEN s.losal AND s.hisal AND s.grade = 5;
Exhibit:
EMP table:



After having finished the certification path to MCPD Enterprise Application Developer 3.5 I had to choose the next exam. I couldn't take .NET 4.0 exams as they were not available yet, so I chose SQL Developer path. I think it is obvious as I can't even recall the application I worked on that didn't have any database layer. Of course sometimes I worked on business layer, but the application did have data layer that was using either Oracle, MS SQL or IBM DB2 database. Being a very good database developer is as much important for a software developer as being a very good software developer. I have seen quite a few solutions where not really bad software developers did very bad job as database developers, which had very bad results on application performance and stability. Those examples encouraged me to stay focused on database development almost on the same level as staying on software development. That's why I used the gap between .NET exams to take one of the database development exams. So far I have taken only one - 70-441 MCTS SQL Server 2005, so my choice was either SQL Server 2008 or Oracle SQL Expert, and I decided to take 1Z0-047 as at the moment I work more with Oracle Database than SQL Server. So as always before starting studying to an exam, I try to find any information on the exam from people who have taken the exam. Unfortunately, there's not much about this exam. Below are two links I found most useful:
Oracle-Database-Expert-Exam-Guide-Reviews
Oracle Forum
The first link gives you some information on the book "OCA Oracle Database SQL Expert Exam Guide: Exam 1Z0-047" and whether the book is sufficient to the exam. Not much information but always some. The forum link contains a lot more information. Here are some most useful suggestions you can find there:
- read the exam topics
- read the Oracle documentations regarding to the topics
- if you don't like the Oracle docs, then get books from amazon, etc.
- practice on daily basis if you don't work as a developer...
- "To be honest I didn't like this exam because I had to read everything 3 times at least, it was really easy to make mistakes..."
- "Anybody who took it will be subject to non disclosure agreements, so would be very limited in their comments. The only thing I can suggest is to look over the topics for the exam and the sample questions and practice. If you know the topics, carefully view the questions then our should be all right. If its your first exam ever then it will seem a little more daunting."
It is not much but gives you some understanding. So my strategy for this exam is to read the following books and ebooks:
- OCA Oracle Database SQL Expert Exam Guide: Exam 1Z0-047
- Oracle Database 11g The Complete Reference
- SQL Language Reference
- Oracle Database Reference
I think both books and ebooks should give me very deep understanding of SQL and Oracle Database 11g. Once I have read them, I will read again information on the exam topics that you can find on the official Oracle web site. That should guarantee that my studying covered all exam topics since one of the reviews of the exam guide book said that the exam covered several topics not mentioned in the book. The exam guide book has 2 complete sample tests so I think before taking the real test they should help me evaluate my skills and show the topics I need to focus. I also believe that the best way to study is by doing the examples, so I will practice each exam topic to make sure I understand it correctly and there's no error in the book. As far as posts on the exam, I will use sample questions presented on the Oracle official exam web site, as I believe they test the knowledge that is more than likely to appear on the exam.
